PANDAS 의 데이터는 어떻게 정의할까?
다음 두 데이터 형태를 사용하여 데이터를 정의하고 각데이터를 연산함
시리즈
어떤 항목에 대한 값들의 묶음. 정확한 정의는 Numpy 기능을 기반으로 만든 Wrapper 패키지로 벡터라이징이 가능하도록 만든 판다스의 모듈이다.
예를 들어, 이름 : 김연아, 송혜교, 김태희 .....
데이터 프레임
이런 시리즈 들의 묶음, 각 시리즈들은 인덱스를 공유함
예를 들어,
시리즈 1 -> 이름 : 김연아, 송혜교, 이효리
시리즈 2 -> 직업: 피겨선수, 배우, 가수
두개를 붙여서 데이터 프레임.
예를 또 들어,
시리즈 1 : 국어 성적
| 국어 |
| 90 |
| 90 |
| 100 |
시리즈 2 : 수학 성적
| 수학 |
| 80 |
| 90 |
| 100 |
공통 특징은 '중간고사 성적' -> 인덱스로 정한다.
인덱스 여러개 붙이면 데이터 프레임이랬으니까 데이터 프레임은 이런 것
| 인덱스\과목 | 국어 | 영어 | 수학 |
| 중간고사 | 90 | 100 | 80 |
| 기말고사 | 90 | 95 | 90 |
| 쪽지시험 | 100 | 100 | 100 |
파이썬을 이용한 데이터 프레임 생성 및 연산
데이터 프레임 생성
2001 과 같은 공통의 인덱스를 입력하지 않으면, 그냥 1행, 2행, 3행 으로 보이지 않는 인덱스가 붙여짐
단, 2001, 2002 와같은 인덱스를 입력해도 1행2행3행 의 인덱스는 같이 생김 이게 디폴트 인덱스라고 생각하면 됨

없는 값은 NaN 으로 표기됨
역행렬
역행렬은 곱해서 1 이 되는 행렬인데 여기서는, 행과 열을 바꿔 원소를 배열한 ‘전치 행렬’ 을 의미
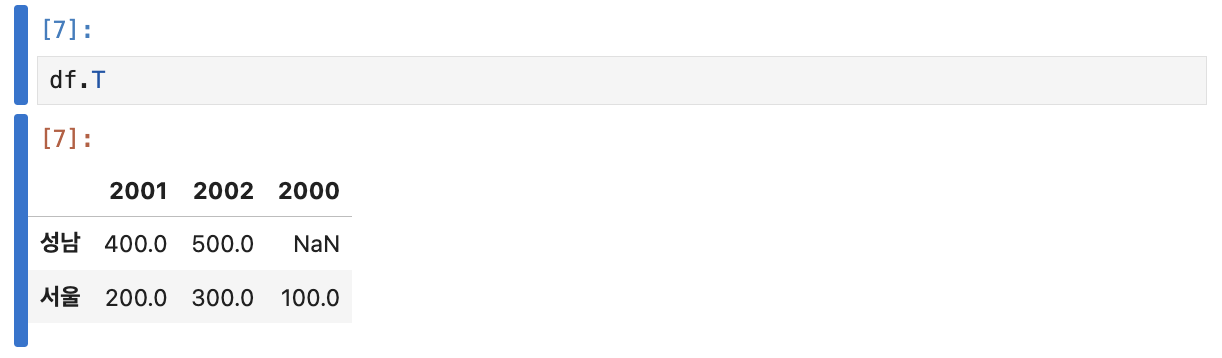
컬럼 순서 재배치

loc
일부 위치의 값들만 선택하여 보여줌

행 또는 열 제거
inplace 를 False 로 주면 원래의 데이터 프레임은 바꾸지 않고 드롭한 상태의 데이터 프레임만 계산해서 보여줌. 즉 df 자체는 맨처음 만들었을 때와 같다. 반대로 True 로 주면 drop을 하여 행이 사라진 저 데이터 프레임으로 df 가 변경됨.
axis ='columns’ 은 말그대로 컬럼을 삭제, 세로줄 자체를 삭제.
메소드 마다 컬럼을 어떻게 지정해야할지 헷갈리니 주의해야한다.

'파이썬 > Pandas' 카테고리의 다른 글
| 데이터 시각화 - 그래프 종류와 해석 (0) | 2024.08.28 |
|---|---|
| 파이썬에서 생성자란 (0) | 2024.07.19 |
| Pandas DataFrame 만들고 연산하기 (2) - 맥, 주피터 사용 (0) | 2024.07.17 |